Pas besoin de ChatGPT pour ça
Ce billet fait suite à une présentation réalisée dans le cadre des TAKE OVER, des cours sur le numérique donnés par des étudiant.e.s pour des étudiant.e.s. Le lien de la présentation est disponible ici et la vidéo de l’atelier est disponible ici.
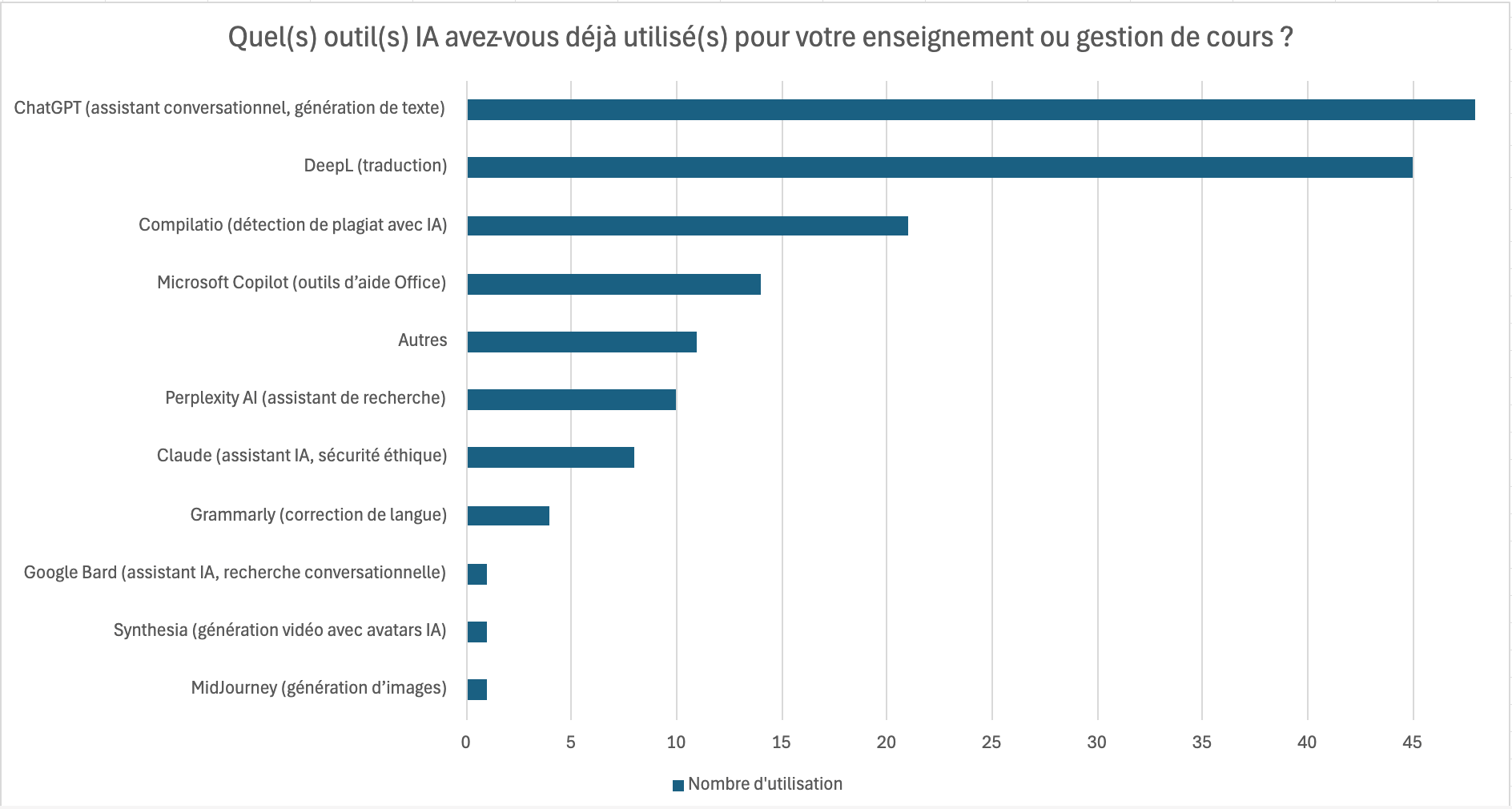
ChatGPT est partout et utilisé par tout le monde. Ce nom est tellement dominant qu’il est pratiquement devenu synonyme du terme « intelligence artificielle ». Pourtant, l’intelligence artificielle est bien plus que ça et nombreux sont les utilisateurs qui gagneraient à en apprendre davantage sur l’IA et à découvrir des alternatives à ChatGPT.
Introduction
Introduction
Nous avons trop souvent l’habitude de parler de l’intelligence artificielle (IA) de manière générale, mais sans nous attarder sur ce que ça représente. À cet égard, on parle souvent de ChatGPT, ce modèle d’intelligence artificielle utilisé par tout le monde, mais sans aller plus loin. Par exemple, on ne le décline pas sous ses différents modèles (GPT-4o, o1, etc.). Pourtant, il existe tellement de modèles en dehors de ceux proposés par OpenAI, tels que les séries Claude (Anthropic), DeepSeek (DeepSeek), Gemma (Google), LLaMA (Meta) et Qwen (Alibaba Cloud).
En réalité, lorsque l’on s’intéresse davantage au sujet, on parle de modèles d’intelligence artificielle établis sur le deep learning (réseau de neurones). Les Large Language Models (LLM pour Large Language Models), basés sur l’architecture Transformers, ne sont qu’une partie de ce qui est fait dans le domaine de l’intelligence artificielle. Bien qu’ils soient très puissants et permettent des interactions en direct, ils souffrent de nombreuses limites comme l’hallucination, qui n’est en réalité pas un bug, mais bel et bien un élément attendu dans ce type de système. Pour en apprendre davantage sur les fondamentaux techniques des LLMs de façon visuelle, vous pouvez en apprendre plus dans la playlist de 3Blue1Brown sur les réseaux de neurones.
Mais il existe un monde gigantesque en dehors des LLMs. On parle par exemple assez souvent des modèles de diffusion pour les images et les vidéos. Mais L’IA est utilisé dans beaucoup de domaines et a adopté énormément d’usages. Par exemple, il n’y a qu’à voir le site web there is an AI for that qui répertorie actuellement plus de 35’000 outils d’IA. Il n’est pas nécessaire de tout connaître, mais il est bien d’utiliser sa curiosité pour voir ce qu’il est possible de faire au-delà de ChatGPT.
Le problème des LLMs propriétaires comme ChatGPT
Le problème des LLMs propriétaires comme ChatGPT
Au sujet des modèles commerciaux tels que ChatGPT utilisés par beaucoup de personnes, peu d’attention est portée sur le fait qu’ils sont en fait possédés par de grandes entreprises. Ces dernières sont les seules à pouvoir créer ces modèles de fondation puisqu’elles disposent de systèmes de calcul très puissants. Ce n’est pas à la portée de tout le monde. Bien que ce soit une grande chance pour nous que ces entreprises permettent au plus grand nombre de profiter de ces modèles (souvent gratuitement), cette situation soulève des questions importantes.
Premièrement, ces modèles commerciaux sont problématiques pour l’environnement parce qu’ils consomment davantage d’énergie que la plupart des systèmes que nous avons créés jusqu’à maintenant. De plus, malgré leur accessibilité grâce à la gratuité de certains modèles propriétaires, ce sont principalement quelques compagnies qui en possèdent le contrôle. Beaucoup de personnes ont vu dans l’ouverture et l’accès à ces modèles une démocratisation de l’IA, mais aussi longtemps que ces modèles seront centralisés et la propriété de grandes compagnies, le terme « démocratisation » ne peut pas être employé.
Deuxièmement, en tant qu’utilisateurs, nous avons tendance à utiliser ces modèles pour presque tout. Par exemple, nous utilisons ChatGPT pour écrire une lettre de motivation ou corriger des fautes d’orthographe. On pourrait se questionner sur la nécessité de devoir utiliser un grand modèle capable de grandes prouesses comme la création de code, l’écriture stylisée ou les raisonnements mathématiques avancés, pour ajouter quelques « s » oubliés dans un petit texte. Est-ce que cette consommation d’énergie est nécessaire ? N’aurions-nous pas des modèles tout aussi performants et moins énergivores ? La parcimonie est nécessaire ici.
De plus, une portion significative des utilisateurs discute librement de choses privées avec ces modèles, ce qui est problématique, car ces données sont ensuite utilisées par les compagnies pour le réentraînement de leurs modèles. Notons également qu’un compte sur ces plateformes centralisant toutes nos conversations permettrait d’établir des profils d’utilisateurs très précis. Ces données pourraient être utilisées à des fins de publicités personnalisées à l’intérieur des discussions.
Quelles sont les alternatives ?
Quelles sont les alternatives ?
DuckDuckGoAI
Heureusement, il y a des solutions pour celles et ceux qui s’intéressent à ces problèmes. Pour la confidentialité, nous pouvons utiliser DuckDuckGoAI qui donne accès à des modèles en ligne d’OpenAI (GPT-40 mini et 03-mini), Anthropic (Claude 2 Haiku), Meta (Llama 7B) et Mistral (Mistral small) gratuitement sans la nécessité d’avoir un compte. La plateforme se charge d’envoyer les requêtes pour nous et donc aucune de nos conversations n’est centralisée dans un seul et même compte. À condition que des informations sensibles ne soient pas transmises, cela garantit une bien meilleure confidentialité. Toutefois, ça ne règle pas forcément le problème environnemental parce que de nombreuses personnes peuvent continuer à utiliser ces grands modèles en ligne pour de petites tâches.
Huggingface Spaces
Nous avons la possibilité d’utiliser une grande variété de modèles d’IA sur la plateforme Huggingface. Ce site donne la possibilité d’utiliser toute une série de modèles gratuitement et sans données collectées. Il suffit de les chercher dans les Huggingface Spaces. Puisque de nombreux fournisseurs de modèles utilisent ce système pour faire de la promotion de leurs produits, il nous est possible de tester des modèles récents et avancés sur Huggingface. Il n’y a pas que des modèles de conversation, mais également des modèles de génération d’image, d’audio ou de vidéo. Notons toutefois qu’il n’est pas garanti que tous les modèles restent disponibles indéfiniment.
SLMs ou Modèles locaux
Une autre approche, qui permet à la fois une meilleure confidentialité et un usage limité d’énergie pour des petites tâches, est l’utilisation de modèles locaux ou Small Language Models (SLM) tels que LLaMA 4, Qwen 3 ou Gemma 3 (il y en a bien plus). Ces modèles se trouvent également sur Huggingface, mais peuvent être téléchargés et utilisés localement. Parce que ces modèles sont beaucoup plus petits et disponibles en différentes tailles, ils peuvent marcher sur nos ordinateurs et restent quand même assez performants pour la taille qu’ils ont. Typiquement, ils sont assez efficaces lorsqu’il faut faire de la traduction ou de la correction textuelle.
Il est aujourd’hui assez simple de les obtenir. Il suffit de choisir un logiciel tel que ollama ou LM Studio. Puis de télécharger un modèle local au travers du logiciel. Notons que les modèles ne sont pas open source mais plutôt open weight qui ont dans la grande majorité des licences permissives, donc pas de restriction pour une utilisation privée. Il existe des ressources francophones disponibles pour les deux logiciels. Une playlist sur ollama et une vidéo sur LM Studio.
Qui dit local, dit indépendance à Internet, ce qui reste un argument assez intéressant. On notera aussi que pour nos amis développeurs, l’utilisation de l’API par le biais des logiciels fournissant ces modèles locaux n’engendre pas de coût contrairement aux modèles commerciaux.
Puisque les modèles sont disponibles directement sur nos ordinateurs, la confidentialité est garantie. Ils ne sont pas aussi puissants que les plus gros modèles commerciaux, mais la plupart du temps, cela suffira pour des tâches textuelles simples. C’est un atout majeur qu’il ne faut pas négliger. Il faut toutefois noter que les SLMs sont beaucoup moins performants que les LLMs (modèles commerciaux) lorsqu’il s’agit de répondre à des questions de connaissance ou de résolution de problème. Mais les petits modèles peuvent combler en bonne partie ce désavantage en utilisant le RAG (Retrieval Augmented Generation). En leur donnant accès à des ressources en local et en ligne, les SLMs comblent leur manque de connaissances.
Notons qu’une des limites de cette approche est de devoir utiliser des modèles plus petits lorsqu’on ne dispose pas de carte graphique assez puissante sur notre ordinateur. Sans cela, les modèles supérieurs à 4b (4 milliards de paramètres) seront très lents. Malgré ces limitations, les modèles locaux restent des alternatives viables aux modèles commerciaux. À l’avenir, ces SLMs vont s’améliorer et devenir de plus en plus performants tout en restant de taille accessible. Pour des tâches spécifiques (surtout après le recours de Fine-Tuning), ils seront vraiment très pratiques et utiles. Voilà pourquoi je recommande l’utilisation de petits modèles locaux pour de petites tâches.
Pas besoin de ChatGPT pour ça
Pas besoin de ChatGPT pour ça
Donc pas besoin de ChatGPT pour ça. « Ça » ? C’est quoi « ça » ? Ce sont des travaux basiques, tels que les résumés simples, les traductions, la correction textuelle, le brainstorming ou la reformulation. Ces tâches peuvent être faites localement et en toute confidentialité en utilisant un SLM. Lorsque des sources sont disponibles, ces modèles sont capables de répondre précisément à des questions dans un domaine spécifique. Pour de nombreuses tâches, nous n’avons pas besoin de ChatGPT ni d’un modèle aussi volumineux. On a simplement besoin d’un modèle compact qui suffit pour répondre à nos emails et écrire des messages, corriger des fautes, traduire nos documents ou tout autre type de tâches de ce type-là. Si vous avez une bonne maîtrise de la programmation, vous pouvez même automatiser des processus localement et gratuitement.
Si l’approche des modèles locaux ne vous plaît pas ou que vous avez besoin de modèles plus grands ou sophistiqués pour répondre à des questions mathématiques, de logique ou de programmation, vous avez toujours la possibilité d’utiliser DuckDuckGoAI qui donne accès gratuitement et de manière confidentielle à de plus grands modèles. Huggingface Spaces et une alternative intéressante qui donne non seulement accès à des LLMs et SLMs de tout genre, mais aussi à des modèles de génération d’audio, d’image ou de vidéo.
Si vous avez un abonnement payant à auprès d’une compagnie de LLMs commerciaux et avez donc accès à de meilleurs modèles, vous pourrez les utiliser pour des problèmes plus costauds. Toutefois, rien ne vous empêche d’utiliser un mélange de toutes ces alternatives présentées ci-dessus.